0. 개요
- 백엔드 개발자에게 DB를 다루는 능력은 매우매우 중요합니다.
- JPA : 영속성 컨텍스트, 연관관계
- Spring Data JPA : 쿼리 메소드, 페이지 정렬
- 폴더 기능 추가하기
1. JPA 이해
ORM이란? (Object-Relational Mapping) :
Object : "객체"지향언어 (자바, 파이썬) - 웹 서버에서 사용
Relational : "관계형" 데이터베이스 (H2, ORACLE, MySQL) - DB에서 사용
Object와 Relational 사이에서 번역을 해주는 것을 ORM 이라고 합니다.
웹 서버를 개발하는 백엔드 개발자와 DB를 관리하는 DBA로 역할이 나뉜 규모가 큰 회사도 있습니다
- ORM 없이도 웹 서버 개발을 할 수 있습니다. 이전에 Repository 역할을 분리해서 DB Query를 작성, 실행을 했었습니다.
- ORM 사용 이유 : ORM이 없는 환경에서는 백엔드 개발자가 비즈니스 로직보다 SQL 작성에 더 많은 노력을 기울어야 합니다. SQL 작성은 단순하고 반복적이며 실수하기도 쉽습니다. 이러한 이유로 웹 서버 개발 언어와 관계형 데이터 베이스 언어의 번역을 해주는 ORM이 등장하게 되었습니다.
- 백엔드 개발자는 DB에대해 굉장히 잘 알고 있어야 합니다. DB 테이블 설계, SQL Query 성능 확보 등을 위해서라도 DB에 대한 지식은 필수적입니다.
JPA란?
- Java Persistant API : 자바 ORM 기술의 표준 명세
- JPA 샘플
@Entity // DB 테이블 역할을 합니다.
@Table(name = "users")
public class User {
// ID가 자동으로 생성 및 증가합니다.
@GeneratedValue(strategy = GenerationType.AUTO)
@Id // PK
private Long id;
// nullable: null 허용 여부
// unique: 중복 허용 여부 (false 일때 중복 허용)
@Column(nullable = false, unique = true)
private String username;
@Column(nullable = false)
private String password;
@Column(nullable = false, unique = true)
private String email;
@Column(nullable = false)
@Enumerated(value = EnumType.STRING) // DB에는 문자열로 저장
private UserRoleEnum role;
@Column(unique = true)
private Long kakaoId;
}
JPA가 없으면?
- 직접 SQL문을 작성해 구현
JPA 사용 트렌드 :
- SQL 매퍼 (MyBatis, JdbcTemplate) 위주 개발
- JPA의 사용 빈도는 급격히 증가중
하이버네이트 (Hiberanate)란? :
- JPA는 표준 명세이고, 이를 구현한 프레임워크이다.
- 사실상 표준으로 사용되며 스프링 부트에서 기본적으로 "하이버네이트"를 사용 중이다.
- 이와 같은 시장에서 경쟁을 통해 결정된 비 공식적 표준을 De facto (디팩토) 라고 한다.
2. JPA 영속성 컨텍스트의 이해
영속성 컨텍스트란? :
- JPA는 ORM 역할을 합니다. ORM은 객체와 DB간 소통을 원할하게 도와주는 역할을 합니다.
- 영속성 컨텍스트 매니저 (Entity context manager)는 객체와 DB의 소통을 효율적으로 관리하는 역할을 의미합니다.
PK (Primary Key)
- 테이블에서 각 row 마다 갖고 있어야만 하는 유일하고 무이한 값 (Null 값 허용 X, Unique O)
- 자연키 vs 인조키 : USERNAME, EMAIL, 주민번호 (비즈니스 조건에서 자연스럽게 만들어진 값) vsv ID (DB에 저장하며 생성한 값)
- 보통 테이블 ID를 PK로 설정
H2 File DB 셋팅 :
spring.h2.console.enabled=true // H2 허용
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.url=jdbc:h2:./myselectdb;AUTO_SERVER=TRUE // MEM 대신 파일 경로를 명시 (파일 DB)
spring.datasource.username=sa
spring.datasource.password=
spring.jpa.properties.hibernate.format_sql=true // Hibernate sql 출력하기
spring.jpa.hibernate.ddl-auto=update
spring.jpa.generate-ddl=true
logging.level.org.hibernate.SQL=debug
logging.level.org.hibernate.type.descriptor.sql=trace
server.port=8090- H2 In-memory DB를 File DB로 변경해 데이터가 사라지지 않게 하기 : mem 대신 파일 경로 작성
- JPA에의해 변경된 SQL 언어 출력 : hibernate.format_sql을 true로 설정
- 간단한 User 엔터티를 작성:
@Setter
@Getter // get 함수를 일괄적으로 만들어줍니다.
@NoArgsConstructor // 기본 생성자를 만들어줍니다.
@Entity // DB 테이블 역할을 합니다.
@Table(name = "users")
public class User {
// nullable: null 허용 여부
// unique: 중복 허용 여부 (false 일때 중복 허용)
@Id // PK, nullable false, unique true
// name으로 필드명 설정
@Column(name = "id", nullable = false, unique = true)
private String username;
@Column(nullable = false, unique = false)
private String nickname;
@Column(nullable = false, unique = false)
private String favoriteFood;
public User(String username, String nickname, String favoriteFood) {
this.username = username;
this.nickname = nickname;
this.favoriteFood = favoriteFood;
}
}- 프로젝트 폴더를 디스크에서 다시 로드 후 myselectdb.mv.db 파일 확인
- 우측 데이터 베이스 탭에서 H2 생성, 경로 추가 "jdbc:h2:file:./myselectdb;AUTO_SERVER=TRUE"
- 연결 타입 embeded 확인, 사용자를 sa로 하고 연결 테스트 진행
영속성 컨텍스트를 확인하는 테스트 코드 구현
- 회원 관리를 위한 Controller, Service, Repository 테스트 코드
Entity 조회, 디버깅 방법 :
- break point 찍기, DB 변경 내역을 확인하기위해 스레드로 설정
3. JPA 영속성 컨텍스트의 1차 캐시의 이해
[JPA/김영한] 영속성이란 무엇일까?
이 글은 김영한님의 JPA 강의 중 3장을 듣고 정리한 내용입니다 :) 강의 : 자바 ORM 표준 JPA 프로그래밍 - 기본편 교재 : 자바 ORM 표준 JPA 프로그래밍🤷♀️ Jpa에서 중요한 것 2가지 ? 객제-디비 매
velog.io
영속성이란? (Persistance)
- 영속성은 프로그램이 종료 되어도 사라지지 않는 데이터의 특성을 의미합니다.-
- 영속성 컨텍스트 : 애플리케이션과 DB 사이에서 엔티티를 영구히 보관하는 가상의 DB 환경 (Spring JPA Persistance Context)
캐시란?
- 요청의 결과를 미리 저장하고 빠르게 사용하기위해 사용됩니다.
- 캐시를 사용하면 관계형 데이터베이스에 접근하는 속도가 훨씬 빨라집니다. 그림에서처럼 메모리 접근이 디스크 접근보다 빠른 것을 볼 수 있습니다. 따라서 Memory에 자주 접근하고 덜 바뀌는 데이터를 저장할 때 캐시를 사용하는 것이 적합합니다.
- 캐시를 쓰는 이유 : 네트워크를 통해 DB에 접근하는 시간 비용은 애플리케이션 서버에서 내부 메모리에 접근하는 시간비용보다 수만, 수십만배 이상 비쌉니다. 따라서 조회한 데이터를 메모리에 캐시해서 데이터베이스 접근 횟수를 줄임으로써 애플리케이션의 성능을 획기적으로 개선합니다.

1차 캐시란? ( == 영속성 컨테이너)
- 영속성 컨텍스트 내부에서 엔티티를 보관하는 가상의 저장소입니다.
- 엔티티 매니저로 영속성 컨텍스트 내부의 1차 캐시를 조회하거나 변경합니다.
- 1차 캐시는 트랜잭션이 완료되는 시점에서 종료됩니다. (OSIV 제외)
- 동일한 트랜잭션 내에서만 1차 캐시가 존재하기 때문에 획기적으로 데이터 베이스의 접근 횟수를 줄여주지 못한다.

엔티티의 4가지 생명주기 :
- 비영속 상태 (new/ transient) : 객체만 생성하고 엔티티와 연결X
- 영속 상태 (meanaged) : @Id 필드로 맵핑된 키와 Entity 값으로 맵핑되어 영속성 컨텍스트에 저장된 상태 (1차캐시, 쓰기지연)
- 준 영속 상태 (detached) : 엔티티가 영속성 컨텍스트에서 분리
- 삭제 상태 : 엔티티 삭제
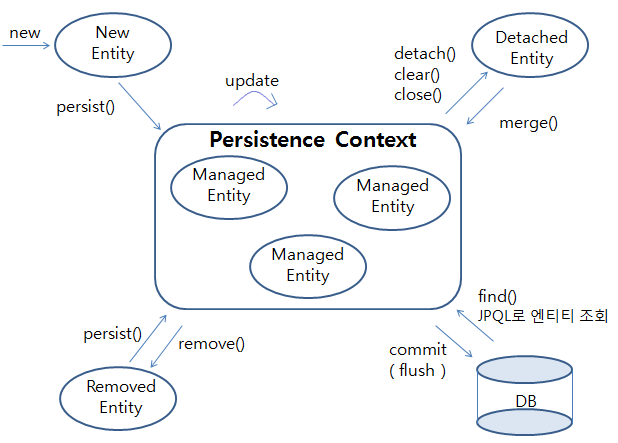
영속성 컨텍스트의 상태변화 (Status Change) 2가지 :
- 비영속 -> 영속 -> 삭제
- 영속 -> 준영속
영속성 컨텍스트의 장점 :
- 1차캐시 : Entity 조회 시 DB보다 먼저 조회되는 캐시, 트랜잭션이 끝나면 지워진다.
- 동일성 보장 : 같은 호출을 반복해도 1차 캐시에 있는 같은 엔티티를 반환하여 동일성을 보장 (JPA는 보장 O, Mybatis는 보장X)
- 쓰기 지연 : 트랜잭션 커밋 시 모아놨던 SQL을 한 번에 DB로 전달
- 변경 감지(더티체킹) : 엔티티 수정 시 개발자가 업데이트나 저장을 하지 않음. 내부적으로 플러시 시점에 스냅샷과 변경된 엔티티를 비교하여 찾고 변경 사항을 감지했으면 UPDATE 쿼리를 쓰기 지연 저장소에 저장. 이후 FLUSH 때 디비로 반영합니다.
- 지연 로딩 : 실제 객체 대신 프록시 객체를 로딩합니다. 해당 객체를 사용하는 시점에서 영속성 컨텍스트를 통해 데이터를 불러옵니다.
영속성 컨텍스트 추가 설명 :
- JPA의 Persistance Context는 Entity를 영구히 저장합니다. (영속성) 즉, 가상의 DB로서 어플리케이션과 데이터 베이스 사이에서 객체를 보관하는 논리적 개념입니다.
- 영속성 컨텍스트는 직접 접근이 불가능하며, 엔티티 매니저를 통해서 접근이 가능합니다. (식별자로 @Id로 지정된 멤버 변수를 사용합니다.)
- EntityManager를 통한 엔티티 저장, 조회 시에 엔티티를 보관하고 관리하고 있습니다. em.persist()
- 트랜잭션을 커밋하는 시점에서 영속성 컨텍스트의 내용이 테이블에 반영됩니다. em.flush()
- 더티 체킹 : 엔티티 객체의 필드값만 변경해주면 별도의 update쿼리를 날리지 않아도 트랜잭션이 끝나는 시점에 해당 테이블의 변경 내용이 반영됩니다.
- 영속성 컨텍스트 내부의 캐시를 1차 캐시라고 합니다. 이 값은 @Id 식별자로 맵핑된 Entity 인스턴스 입니다. 만약 entityManager.find(), 조회하는 메소드가 호출되면 먼저 1차 캐시에서 Entity를 찾고, 못찾을 시 DB를 조회합니다.
- 트랜잭션 (쓰기 지연) 수행 : EntityManager는 트랜잭션을 커밋하기 직전까지 DB에 Entity를 저장하지 않습니다. 대신 영속성 컨텍스트 내부의 SQL 저장소에 생성한 쿼리를 저장합니다. 이후 커밋을 할 때 저장해둔 쿼리를 DB에 보냅니다.
- 트랜잭션 커밋 시 EntityManager는 영속성 컨텍스트와 쓰기 지연된 SQL을 함께 flush() 합니다. 이는 곧 영속성 컨텍스트의 내용을 DB로 동기화하는 작업으로서 등록, 수정, 삭제된 Entity를 DB에 반영합니다. 동기화 작업을 진행한 후 데이터베이스 트랜잭션 커밋을 완료합니다.
- 영속성 컨텍스트는 flush() 한 후의 Entity 상태를 복사해 스냅샷을 저장합니다. Entity에 변경사항이 생길 경우 이 스냅샷을 비교해 찾습니다. 이렇듯 변경사항을 감지했으면 수정 쿼리를 만들어 SQL 저장소에 쓰기지연을 걸어둡니다. 변경 감지는 영속 상태의 엔티티에만 적용됩니다.
플러시란?
- 영속성 컨텍스트의 변경 사항을 DB와 동기화
플러시하면
- 변경감지
- 수정된 엔티티를 쓰기 지연 SQL 저장소에 등록
- 저장소의 모아둔 쿼리를 DB로 함께 전달
- 1차 캐시와 무관하게 쓰기 지연 저장소를 한 번에 디비에 반영하는 과정. 동기화는 트랜잭션 커밋 직전에 이루어지기 때문.
@Transactional을 사용할 경우 : "쓰기 지연"
- .save() 메소드 호출 시 SQL 쿼리 쓰기 지연 저장소에 저장되어 대기함 -> DB에 데이터 반영 X
- Transactional 처리 된 함수가 종료가 될 때 DB 커밋 직전 Flush()가 호출되면서 모아 뒀던 쓰기 지연 저장소의 SQL 쿼리가 실행됨.
2차 캐시란?
- JPA에서 어플리케이션이 공유하고 있는 캐시를 2차 캐시라고 합니다.
- 트랜잭션이 완료되는 시점에 종료되는 1차 캐시와 달리 2차 캐시는 애플리케이션을 종료할 때까지 유지됩니다.
- 2차 캐시를 적절히 활용하면 데이터베이스 조회 횟수를 획기적으로 줄일 수 있습니다.
- 하이버네이트를 포함한 대부분 JPA 구현체들은 2차캐시를 지원합니다.
2차 캐시를 사용하는 이유 :
- 동시성 극대화
- 원본인캐시화된 객체를 반환하지 않고 복사본을 반환한다.
- 복사본을 반환하지 않고 캐시 객체를 그대로 반환할 경우 같은 객체를 동시에 수정하는 문제가 발생 할 수 있으며 동시 수정 문제를 해결하기 위해 락을 걸 경우 동시성이 떨어지는 문제도 발생한다. 따라서 락에 비해 객체를 복사하는 비용은 아주 저렴하다고 할 수 있다.
- 동시성은 싱글 코어에서 멀티 스레드를 동작시키기위한 방식으로 멀티 태스킹을 위해 여러 개의 스레드가 번갈아 실행되는 성질을 말합니다. 동시성을 이용한 싱글코어의 멀티태스킹은 각 스레드들이 병렬적으로 실행되는 것처럼 보이지만 사실은 번갈아 가며 조금씩 실행되고 있는 것입니다. 동시 수정 문제를 해결하기위해 락을 걸면 성능과 동시성이 떨어지기 때문에 2차 캐시는 원본 대신 복사본을 반환합니다.

4. JPA 연관관계의 이해
DB의 연관관계란?
- 비즈니스 요구사항 예시 : "고객은 1개의 음식을 주문할 수 있다."
- 고객 테이블과 음식 테이블이 있다고 하자. 이 때, 고객이 음식을 주문하면 주문 정보를 어느 테이블에 저장해야 할까?
1) 고객 테이블에 주문 정보를 넣은 경우 : 문제점 - 중복된 회원 정보
2) 음식 테이블에 주문 정보를 넣는 경우 : 문제점 - 중복된 음식 정보
3) 해결책 : 주문 테이블을 추가하여 연관관계를 맵핑함.
- 회원 1명은 주문 N 개를 할 수 있다. => 회원 : 주문 = 1 : N 관계
- 음식 1개는 주문 N 개에 포함될 수 있다. => 음식 : 주문 = 1 : N 관계
- 결론적으로 회원과 음식과의 관계는 N : M 이다. => 회원 : 음식 = N : M

JPA의 연관관계란?
- JPA는 Entity 클래스의 필드 위에 연관관계 어노테이션을 추가해 줌으로서 연관관계를 설정해 줍니다.

- JPA 코드 구현 예시) "주문 : 음식 = 1 : N" 관계이며 "주문 : 쿠폰 = 1 : 1" 관계 입니다.
@Entity
public class Order {
@OneToMany
private List<Food> foods;
@OneToOne
private Coupon coupon;
}- 예시2) "점주 : 가게 = N : 1" 관계입니다.
@Entity
class Owner {
@ManyToOne
private Restaurant restaurant;
}- 예시3) "고객 : 놓아요한 가게 = N : M" 관계입니다.
@Entity
class User {
@ManyToMany
private List<Restaurant> likeRestaurant;
}
Spring Data JPA란?
- JPA 사용에 편리성을 제공합니다. JPA를 스프링에서 Wrapping합니다.
- JPA를 사용할 때 스프링 개발자들은 필수적으로 생성해야 하는 예상 가능하고 반복적인 코드들을 작성해야 했습니다. 이이를 Spring Data JPA가 대신 작성해 줍니다.
- Repository 인터페이스만 작성하면, 필요한 구현을 스프링이 대신 작성합니다.
- Spring Data JPA : JPARepository를 상속받아 사용합니다.
public interface UserRepository extends JpaRepository<User, String> { // <객체, PK>를 전달
}- Spring Data JPA의 기본 제공 기능 :
// 1. 상품 생성
Product product = new Product(...);
productRepository.save(product);
// 2. 상품 전체 조회
List<Product> products = productRepository.findAll();
// 3. 상품 전체 개수 조회
long count = productRepository.count();
// 4. 상품 삭제
productRepository.delete(product);- ID 외 필드에 대한 추가 기능을 interface만 선언해주면 구현을 Spring Data JPA가 대신 해줍니다.
Spring Data JPA - Reference Documentation
Example 119. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io
public interface ProductRepository extends JpaRepository<Product, Long> {
// (1) 회원 ID 로 등록된 상품들 조회
List<Product> findAllByUserId(Long userId);
// (2) 상품명이 title 인 관심상품 1개 조회
Product findByTitle(String title);
// (3) 상품명에 word 가 포함된 모든 상품들 조회
List<Product> findAllByTitleContaining(String word);
// (4) 최저가가 fromPrice ~ toPrice 인 모든 상품들을 조회
List<Product> findAllByLpriceBetween(int fromPrice, int toPrice);
}
5. 페이징 및 정렬 설계
페이징이란?
- Pagination : 콘텐츠를 페이지에 분리하여 탐색할 수 있는 숫자 형식의 링크를 다는 것
- Infinite scroll : 사용자가 페이지 하단에 도달했을 때, 콘텐츠가 계속 로드 되는 사용자 경험, 끝없는 정보 흐름
설계 :
- Client -> Server
1) 서버로 전달할 정보 :
- page : 조회할 페이지 번호 (1부터 시작)
- size : 한 페이지에 보여줄 상품 갯수 (10개 고정)
2) 정렬 :
- sortBy : id, title, lprice, createdAt(id와 동일)
- isAsc : 오름차순(true), 내림차순(false)
- Server -> Client :
1) 클라이언트로 전달할 정보 :
- number : 조회된 페이지 번호 (0부터 시작)
- content : 조회된 상품 정보 배열
- size : 한 페이지에 보여줄 상품의 갯수
- numberOfElements : 실제 조회된 상품의 갯수
- totalElement : 전체 상품 갯수
- totalPages : 전체 페이지 수 = totalElement / size (올림)
- first : 첫 페이지인가 (boolean)
- last : 마지막 페이지인가 (boolean)
구현 :
ProductController :
@GetMapping("/api/products")
public Page<Product> getProducts(
@RequestParam("page") int page,
@RequestParam("size") int size,
@RequestParam("sortBy") String sortBy,
@RequestParam("isAsc") boolean isAsc,
@AuthenticationPrincipal UserDetailsImpl userDetails
) {
long userId = userDetails.getUser().getId();
page = page - 1;
// 응답 보내기
return productService.getProducts(userId, page, size, sortBy, isAsc);
}ProductService :
public Page<Product> getProducts(Long userId, int page, int size, String sortBy, boolean isAsc) {
Sort.Direction direction = isAsc ? Sort.Direction.ASC : Sort.Direction.DESC;
Sort sort = Sort.by(direction, sortBy);
Pageable pageable = PageRequest.of(page, size, sort);
return productRepository.findAllByUserId(userId, pageable);
}ProductRepository :
public interface ProductRepository extends JpaRepository<Product, Long> {
Page<Product> findAllByUserId(Long userId, Pageable pageable);
}
테스트용 더미 데이터 생성하기 :
@Component
public class TestDataRunner implements ApplicationRunner {
@Autowired
UserService userService;
@Autowired
ProductRepository productRepository;
@Autowired
UserRepository userRepository;
@Autowired
PasswordEncoder passwordEncoder;
@Autowired
SearchService itemSearchService;
@Override // ApplicationRunner의 run 함수는 처음 스프링이 기동이 될 때에 아래 코드가 실행됩니다.
public void run(ApplicationArguments args) throws Exception {
// 테스트 User 생성
if (!userRepository.findByUsername("슈가").isPresent()) {
User testUser = new User("슈가", passwordEncoder.encode("123"), "sugar@sparta.com", UserRoleEnum.USER);
testUser = userRepository.save(testUser);
// 테스트 User 의 관심상품 등록
// 검색어 당 관심상품 10개 등록
createTestData(testUser, "신발");
createTestData(testUser, "과자");
createTestData(testUser, "키보드");
createTestData(testUser, "휴지");
createTestData(testUser, "휴대폰");
createTestData(testUser, "앨범");
createTestData(testUser, "헤드폰");
createTestData(testUser, "이어폰");
createTestData(testUser, "노트북");
createTestData(testUser, "무선 이어폰");
createTestData(testUser, "모니터");
} else {
System.out.println("테스트 데이터 생략");
}
}
private void createTestData(User user, String searchWord) throws IOException {
// 네이버 쇼핑 API 통해 상품 검색
List<ItemDto> itemDtoList = itemSearchService.searchItems(searchWord);
List<Product> productList = new ArrayList<>();
for (ItemDto itemDto : itemDtoList) {
Product product = new Product();
// 관심상품 저장 사용자
product.setUserId(user.getId());
// 관심상품 정보
product.setTitle(itemDto.getTitle());
product.setLink(itemDto.getLink());
product.setImage(itemDto.getImage());
product.setLprice(itemDto.getLprice());
// 희망 최저가 랜덤값 생성
// 최저 (100원) ~ 최대 (상품의 현재 최저가 + 10000원)
int myPrice = getRandomNumber(MIN_MY_PRICE, itemDto.getLprice() + 10000);
product.setMyprice(myPrice);
productList.add(product);
}
productRepository.saveAll(productList);
}
public int getRandomNumber(int min, int max) {
return (int) ((Math.random() * (max - min)) + min);
}
}
6. 폴더 기능 추가하기
폴더 별로 관심상품을 저장/관리 할 수 있는 기능을 추가합니다.
요구사항 :
- 폴더 생성 : 회원 별로 1~N개의 폴더를 생성할 수 있습니다.
- 관심 상품 폴더 설정 기능 : 관심 상품은 N개의 폴더에 설정할 수 있습니다. 관심 상품은 오직 생성된 폴더만 추가할 수 있습니다.
- 폴더 별 조회
테이블 설계 :
폴더 테이블에 들어갈 정보 :
- 폴더명
- 유저 아이디 -> 회원 테이블의 아이디임을 맵핑 해주어야함. JPA 연관관계를 활용할 예정
회원 : 폴더 = 1 : N
- User 테이블에서 List<Folder>는 @OneToMany로 설정
- Folder 테이블에서 userId 는 @ManyToOne으로 설정 (Has-a 관계)
- JPA 연관관계가 매핑이되면 DB 상으로 관계가 설정되어 외래키로 객체를 참조할 수 있다.
- DB 상으로 외래키가 존재하면 맵핑된 객체의 존재 여부를 확인합니다. 이를 통해 데이터의 무결성을 보장합니다.
JPA 연관관계 설정 방법 :
@ManyToOne
@JoinColumn(name = "USER_ID", nullable = false)
private User user;- @JoinColumn : name은 외래키명을 설정합니다. nullable이 false임으로 user값이 필수입니다. 만약 nullable이 true인 경우 공용폴더라고 볼 수 있습니다.
구현 :
@Entity
public class User {
...
@Column
@OneToMany
private List<Folder> folders;
...
}
@Entity
public class Folder {
...
@ManyToOne
@JoinColumn(name = "USER_ID", nullable = false)
private User user;
}
관심 상품 별 폴더 추가 구현
요구사항 :
- 관심상품은 0~N 개의 폴더를 설정할 수 있습니다.
- 관심상품을 등록한 시점에는 어느 폴더에도 저장되지 않습니다.
- 폴더에는 여러개의 상품을 저장할 수 있습니다.
- 상품 : 폴더 = N : M
구현 :
Product.java :
@ManyToMany
private List<Folder> folderList = new ArrayList<>();
...
public void addFolder(Folder folder) {
this.folderList.add(folder);
}
폴더 별 관심 상품 조회 구현 :
public interface ProductRepository extends JpaRepository<Product, Long> {
Page<Product> findAllByUserIdAndFolderList_Id(Long userId, Long folderId, Pageable pageable);
}
7. 채워져야 할 것
- jpa 연관관계 : 양방향, 일방향, fetch
8. 숙제
- 중복된 폴더명 생성 이슈 해결하기
- 테스트코드 에러 해결하기
'웹 개발 > 스프링' 카테고리의 다른 글
| [스프링 부트 심화] AOP, Transaction (0) | 2023.04.27 |
|---|---|
| [스프링 부트 심화] 테스트 프레임워크 (0) | 2023.04.19 |
| [스프링 부트 심화] 스프링 시큐리티 - 로그인, 회원가입 구현 (1) | 2023.04.17 |
| [스프링 부트 심화] 스프링 시큐리티 (0) | 2023.04.17 |
| [스프링 부트 심화] HttpEntity, ResponseEntity, HttpStatus (0) | 2023.04.13 |



